はじめに¶
機械学習を学び始めた六角レンチです。
計算資源いっぱいほしい
初めての機械学習としてMNISTやってみたので記事にしたいと思います
まずMNISTってなに?¶
手書きの数字を識別するデータセット。
適当に書くと、28x28の白黒画像が60000枚くらいあるので、そこからどれがどの数字か識別できるようにして、最終的にテスト用の10000枚の画像を識別できるようになってねって感じの物である。
データが綺麗に成形されていて、わかりやすい目標で、負荷も軽いので機械学習を学ぶには最適なデータセットである。
環境¶
デスクトップパソコン¶
- CPU
core i7 4770 - GPU
nvidia GTX 960 - OS
windows 10
CPUが雑魚過ぎるので正直買い換えたい(でもお金ない)
ノーパソ¶
- CPU
core i7 8750H - OS
windows 11 24H2
一応今回作るプログラムはGPUがなくても動く(CPUでも動く)
でもGPUを使う場合と比べて超遅いのでできるだけGPUを使おう
使うライブラリ¶
- PyTorch
機械学習のためのライブラリ
モジュール名はtorchになっている
ライブラリ名とモジュール名が違うのはPythonあるある - torchvision
Pytorchの画像関係で便利なものが色々入ったライブラリ
エコシステム的な感じ
インストールは普通にpipを使う
pip install torch torchvision
cuda(GPU)を使えるようにするには(ここ押すと開くよ)
cudaは、普通にインストールしても入らないので、pytorch公式ページの下部分にあるInstall PyTorchから、cuda対応のpytorchをpipでインストールする必要がある
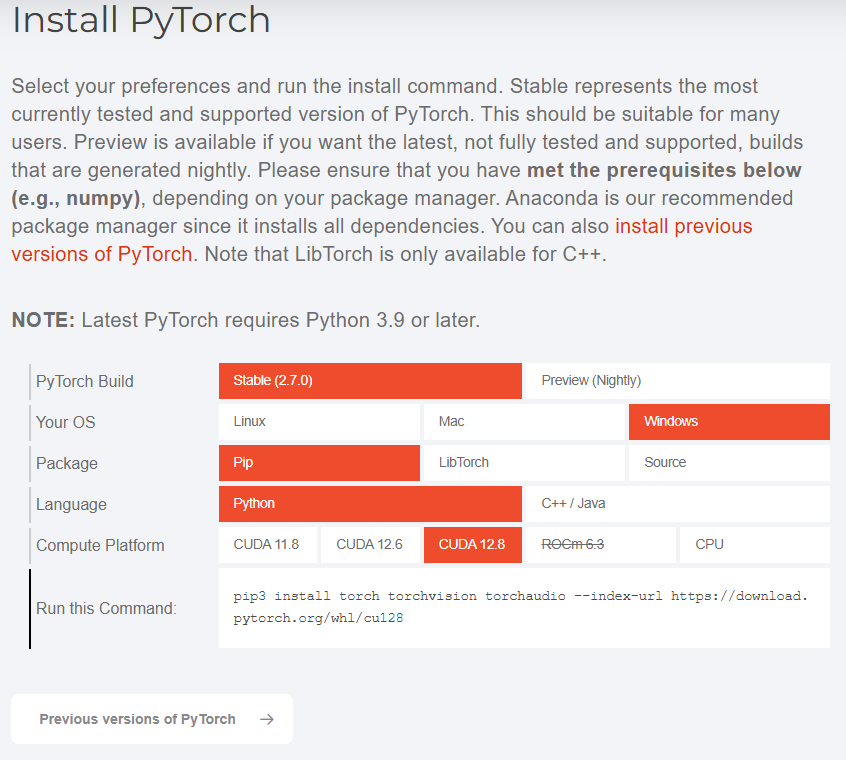
要はcudaを使いたい場合使うコマンドを次のものにすればいいだけ
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128
CUDA 12.8に対応したPyTorchがインストールされる。
CUDA 12.8って何?ってなるかもしれないが、多分CUDA SDKのバージョンのことである。
https://en.wikipedia.org/wiki/CUDA#GPUs_supported
上のwikipediaのページにCUDA SDKと対応するGPUのバージョンが載っているが、CUDA SDK 12.8(2025年5月現在最新のやつ)でもMaxwellまで対応している。
MaxwellはGTX960とかの世代(10年前)なので、大抵の場合最新バージョンをインストールしておいて大丈夫である。(自分GTX960使ってるからギリギリだったけど)
GPUのドライバーも合わせる必要がある。
https://docs.nvidia.com/deploy/cuda-compatibility/
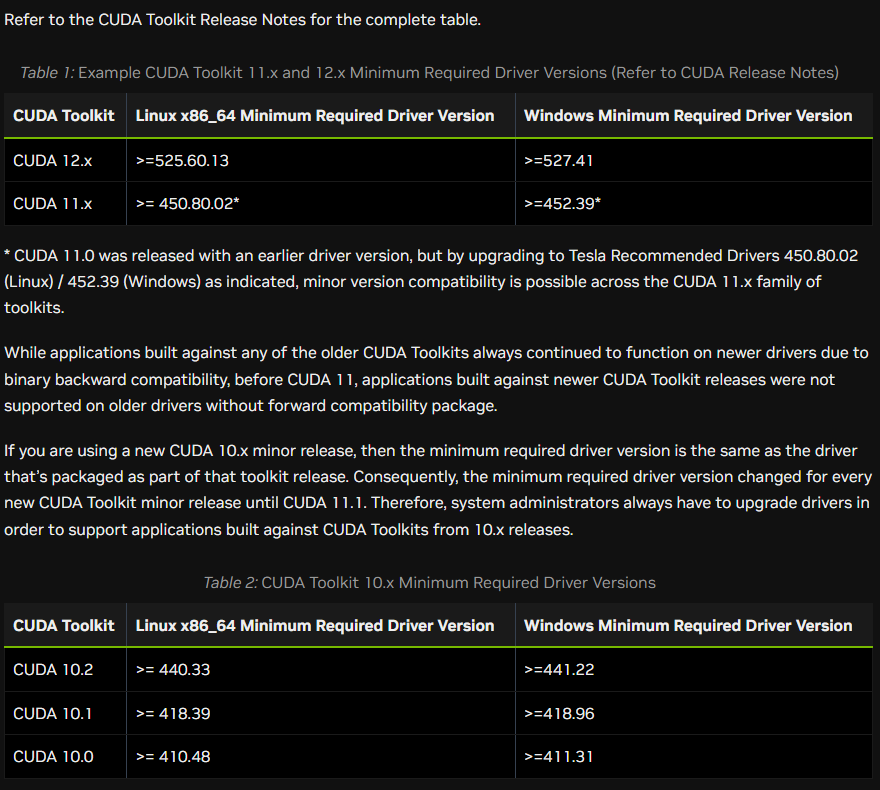
この画像は上の公式サイトのスクショだが、windowsでCUDA 12.8を使う場合はドライバーのバージョンが527.41以上である必要がある。
調べてみたところ、どうやら2022年の12月5日にリリースされたドライバらしい。
なので3年くらい更新してない人は更新した方がいいかもしれない。
もしどうしてもドライバのバージョンを上げられない場合は、下の記事を参考にするといい https://qiita.com/tand826/items/3f78860f4f432c1fb0e4
GPUの処理速度はCPUと比べてとんでもなく速いので、使える場合は使うようにしよう
MNISTを学習するプログラム¶
下のプログラムで、どこがどういう動きをしているのか解説しながら説明していきます
from torch import nn, optim, no_grad, max as torch_max, set_default_device, Generator
from torch.cuda import is_available as cuda_available
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
class MNISTModel(nn.Module):
def __init__(self):
super().__init__()
self.fc_layer = nn.Sequential(
nn.Flatten(), # 平滑化
nn.Linear(28 * 28, 128), # 28 * 28 入力、128出力
nn.ReLU(),
nn.Linear(128, 64), # 128 入力、64出力
nn.ReLU(),
nn.Linear(64, 10), # 10 出力 (0-9の数字分類用
)
def forward(self, x):
x = self.fc_layer(x)
return x
if __name__ == "__main__":
# デバイスの設定
use_device = "cuda" if cuda_available() else "cpu"
set_default_device(use_device)
generator = Generator(device=use_device)
learning_rate = 0.001
batch_size = 32
epochs = 5
print(f"Using {use_device} for training.")
print("Loading MNIST dataset...")
# MNISTデータセットの読み込み
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root="./data", train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root="./data", train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, generator=generator)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, generator=generator)
# モデルの初期化
model = MNISTModel().to(use_device) # モデルをデバイス(gpu)に移動
loss_fn = nn.CrossEntropyLoss() # 損失関数
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 最適化手法
print("Training the model...")
# モデルの訓練
model.train() # モデルを訓練モードに切り替え
for epoch in range(epochs):
running_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(use_device), target.to(use_device) # データをデバイスに移動
optimizer.zero_grad() # 勾配の初期化
output = model(data) # モデルの出力
loss = loss_fn(output, target) # 損失の計算
running_loss += loss.item() # 損失の累積
loss.backward() # 勾配の計算
optimizer.step() # パラメータの更新
print(f"Epoch {epoch + 1}/{epochs}, Loss: {running_loss / len(train_loader):.4f}") # エポックごとの損失を表示
model.eval() # モデルを評価モードに切り替え
print("Training complete.")
print("Evaluating the model...")
# モデルの評価
correct = 0
total = 0
with no_grad(): # 勾配計算を無効化
for data, target in test_loader:
data, target = data.to(use_device), target.to(use_device) # データをデバイスに移動
output = model(data) # モデルの出力
_, predicted = torch_max(output.data, 1) # 最大値のインデックスを取得
total += target.size(0) # 全体のサンプル数をカウント
correct += (predicted == target).sum().item() # 正解数をカウント
print(f"Accuracy: {100 * correct / total:.2f}%") # 精度を表示
import節¶
from torch import nn, optim, no_grad, max as torch_max, set_default_device, Generator
from torch.cuda import is_available as cuda_available
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
一応それぞれ解説すると(ここ押すと開くよ)
torchnn
ニューラルネットワーク関係の物が入ったモジュール
例えばnn.Moduleはニューラルネットワーク関係の基本クラスである。optim
最適化手法関係の物が入ったモジュール
最適化手法ってなんやねんってなるが、要はどの塾を選ぶかみたいな感じ(自分塾行ったことないのでよくわからんけど)no_grad
勾配計算(gradient)を無効化するためのコンテキストマネージャ(with文で使うやつ、builtinのopenとかと同じ)
評価時は勾配計算しない(誤差逆伝搬する必要がない)ので、これを使うとメモリ節約できる。max (torch_max)
最大値を取得する関数
普通のmax関数と違うのは、PyTorchのテンソルに対して使えるところ
テンソルっていうのはPyTorchで使うデータの形である。
そのまま使うとbuiltinのmax関数と被るので、torch_maxという名前でimportしている。
torch.cudais_available (cuda_available)
CUDAが使えるかどうかを判定する関数
CUDAはGPUを使うためのライブラリ的なやつである。
Pythonで例えるとmultiprocessingみたいな感じの存在
この関数がTrueを返す場合はCUDA(GPU)が使える
そのままの名前だとなにが何だかわからないので、cuda_availableという名前に変えている。
torch.utils.dataDataLoader
データローダーを作成するクラス
これを使うことでデータセットから効率的にデータを読み込むことができる。
torchvisiondatasets
色々なデータセットを扱うためのモジュール
MNISTやCIFAR-10などのデータセットが用意されている。transforms
データの前処理を行うためのモジュール
例えば、画像をテンソルに変換したり、正規化したり、回転したり、ずらしたり、切り抜いたりすることができる。
モデル¶
class MNISTModel(nn.Module):
def __init__(self):
super().__init__()
self.fc_layer = nn.Sequential(
nn.Flatten(), # 平滑化
nn.Linear(28 * 28, 128), # 28 * 28 入力、128出力
nn.ReLU(),
nn.Linear(128, 64), # 128 入力、64出力
nn.ReLU(),
nn.Linear(64, 10), # 10 出力 (0-9の数字分類用
)
def forward(self, x):
x = self.fc_layer(x)
return x
普通のFNN(全結合)モデルである。
nn.Sequentialは処理をいい感じにまとめてくれる便利な奴である。
処理を順番に見ていくと
nn.Flatten()
画像データ(28x28)を平滑化(28*28 = 784)
要は二次元配列を一次元配列に変えてるだけnn.Linear(28 * 28, 128)
784個のノードと128個のノードを接続
パラメータ数は784*128 = 100352個
10万個もパラメータあるの!?と思うかもしれないが、CPUやGPU等からしたら全然計算可能である。
正直自分もびっくりしたnn.ReLU()
活性化関数
関数の中身はlambda x: 0 if x <= 0 else xである。
勘のいい人なら気づいてしまうと思うが、実はこれx=0において微分不可能である。
でもそこらへんガバガバで、x=0のとき微分の値を0にしている。
計算量が少ないので、よく使われる活性化関数である。
ReLUが何の略なのかは謎。nn.Linear(128, 64)
128個のノードと64個のノードを接続
パラメータ数は128*64 = 8192個
前のに比べたらかわいいnn.ReLU()
上と同じnn.Linear(64, 10)
64個のノードと10個のノードを接続
パラメータ数は64*10 = 640個
最後の10個のノードはそれぞれ0~9の数字に対応している。
後述する損失関数であるnn.CrossEntropyLoss()で、内部的にsoftmax関数(それぞれのパラメータを確率に変換する感じのやつ)が使われているので、出力は確率のような形になる。
合計パラメータ数は100352 + 8192 + 640 = 109184個。
forward関数は推論するときに通す関数である。
データがさっき説明した処理を通って行く感じ
変数とかの設定¶
# デバイスの設定
use_device = "cuda" if cuda_available() else "cpu"
set_default_device(use_device)
generator = Generator(device=use_device)
learning_rate = 0.001
batch_size = 32
epochs = 5
print(f"Using {use_device} for training.")
use_device
使う装置
GPUならcuda、CPUならcpu。generator
多分乱数の生成器
後述のデータローダー作成時にこれを使うがGPUを使う場合これをdevice="cuda"で初期化して使わないと自分の環境ではバグる、謎。learning_rate
学習率
どれくらいの速度で学習していくか決める。大きすぎると最適な値に収束しないし、小さすぎると学習が進まないので難しい。
ここでは0.001にしてるけど、0.005くらいが自分としてはちょうどいいと感じた。batch_size
バッチサイズとかミニバッチサイズとか言われたりするやつ
人間で例えると英単語を一日20単語覚える感じで進めるか、100単語覚える感じで進めるかみたいな
増やせば増やすほど学習が速くなるが、GPUのメモリ使用量も同じように増えるので注意が必要。
自分は1024にしてるepochs
エポック数
学習を繰り返す数、このコードは学習を速く終わらせるために5だけど10くらいに増やすといい感じ。
途中のset_default_device関数はPyTorchで計算するときに使う装置の設定。
set_default_device("cuda")でGPUを使うようになる。
データセット関係¶
print("Loading MNIST dataset...")
# MNISTデータセットの読み込み
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root="./data", train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root="./data", train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, generator=generator)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, generator=generator)
transform
なんかかっこいい名前をしているが、データの加工をするやつである。
transforms.Composeはnn.Sequentialと同じ感じで、処理をいい感じにまとめてくれるやつである。
今回は特に画像加工したりしないでTensor型(pytorchで使う型)にして正規化(データの偏りをちょっと修正する感じ)してるだけtrain_dataset、test_dataset
データセット
今回のデータセットの場合、トレーニング時と評価時でデータセットがわかれているので別々で用意する。root
引数で指定したディレクトリにデータセットがダウンロードされる
相対パス指定だと、実行したディレクトリからの相対パスになるので注意。train
Trueならトレーニング用データセット、Falseならテスト用データセットdownload
データセットが指定したディレクトリにない場合、ダウンロードするかどうか
もしダウンロードしたくない場合はFalseにする。transform
前述のtransformを指定するための引数。 これを指定することで、データセットの画像が自動で加工される。
train_loader、test_loader
データセットと同様データローダーもトレーニング時とテスト時でわかれている
第一引数としてデータセットを要求するbatch_size
一度に読み込むデータの数、つまりミニバッチサイズである。shuffle
データをシャッフルするかどうか、トレーニング時はTrueにしておくといい感じ。
テスト時はシャッフルしても意味がないのでFalseにしている。generator
乱数生成器、先述のGeneratorを指定する。
計算関係¶
# モデルの初期化
model = MNISTModel().to(use_device) # モデルをデバイス(gpu)に移動
loss_fn = nn.CrossEntropyLoss() # 損失関数
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 最適化手法
model
先ほど定義したMNISTModelをインスタンス化している。
GPUを使う場合は.to(use_device)でGPU(cuda)に移動しないと、GPUを使って計算できないので注意loss_fn
損失関数
ここではnn.CrossEntropyLoss()を使っている。
分類問題でよく使われる関数で、先述したようにsoftmax関数を内部で使って確率に変換して判別してくれる。optimizer
最適化手法
ここではoptim.Adamを使っている。
Adamは他の手法に比べて安定してて使いやすい(らしい、自分他の手法使ったことない)ので使っている。
model.parameters()でモデルのパラメータを渡している。
lr=learning_rateで学習率を指定している。
学習¶
print("Training the model...")
# モデルの訓練
model.train() # モデルを訓練モードに切り替え
for epoch in range(epochs):
running_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(use_device), target.to(use_device) # データをデバイスに移動
optimizer.zero_grad() # 勾配の初期化
output = model(data) # モデルの出力
loss = loss_fn(output, target) # 損失の計算
running_loss += loss.item() # 損失の累積
loss.backward() # 勾配の計算
optimizer.step() # パラメータの更新
print(f"Epoch {epoch + 1}/{epochs}, Loss: {running_loss / len(train_loader):.4f}") # エポックごとの損失を表示
model.eval() # モデルを評価モードに切り替え
print("Training complete.")
まず、model.train()でモデルを訓練モードに切り替える。
訓練モードにすると、ドロップアウトやバッチ正規化などの挙動が変わる。(今回の場合それらを使ってないのでやっても何も変わらないけど、一応変えておく)
for epoch in range(epochs):でエポック数分だけ学習を繰り返す。
running_lossはエポックごとの損失を累積するための変数である。
for batch_idx, (data, target) in enumerate(train_loader):でデータローダーからデータを読み込む。
その後、読み込んだデータをto(use_device)で使うデバイスに移動させる。(これをしないとGPUを使って計算できない)
1エポック毎の学習の流れはこんな感じ
optimizer.zero_grad()
勾配を初期化する。
勾配は前のバッチの勾配が残っているので、毎回初期化しないと累積されてしまう。output = model(data)
モデルにデータを通して出力を得る。
ここでモデルのforward関数が呼ばれる。
model.forward(data)と書いても同じ意味になる。loss = loss_fn(output, target)
損失関数を使って損失を計算する。
outputはモデルの出力、targetは正解ラベル。
ここで損失が計算される。
ここで注意すべき点として、lossはテンソルである。(int型じゃない)running_loss += loss.item()
損失を累積する。
loss.item()は損失の生の値を取得するためのメソッドである。(中身が一つの場合テンソルからint型に変換する)loss.backward()
勾配を計算する。
ここで誤差逆伝搬が行われる。
誤差逆伝搬をlossから行えるのおもしろいよねoptimizer.step()
最適化手法を用いてモデルのパラメータを更新する。
そして最後のprint関数を使って、このエポックにおける損失の平均値を表示する。
この一連の流れを通して、モデルはデータから学習し、パラメータが更新されていく。
最後のmodel.eval()でモデルを評価モードに切り替える(訓練モードを切る)のを忘れないようにしよう。
評価¶
print("Evaluating the model...")
# モデルの評価
correct = 0
total = 0
with no_grad(): # 勾配計算を無効化
for data, target in test_loader:
data, target = data.to(use_device), target.to(use_device) # データをデバイスに移動
output = model(data) # モデルの出力
_, predicted = torch_max(output.data, 1) # 最大値のインデックスを取得
total += target.size(0) # 全体のサンプル数をカウント
correct += (predicted == target).sum().item() # 正解数をカウント
print(f"Accuracy: {100 * correct / total:.2f}%") # 精度を表示
correctは正解数、totalは全体のサンプル数を入れる変数。
まず、no_grad()を使って勾配計算を無効化する。
勾配計算を無効化することで、メモリの使用量を減らすことができる。
その後、評価用データローダーからデータを読み込み、デバイスに移動させる。
その後の流れとしては
output = model(data)
モデルにデータを通して出力を得る。_, predicted = torch_max(output.data, 1)
最大値のインデックスを取得する。
torch_max関数(torch.max)の説明として良い記事を見つけた
わかりやすい説明だったので、そっち読んでほしい
説明書くのめんどくさがっているだけである。
返り値の1引数目は最大値の値で今回はいらないので捨てている。total += target.size(0)
全体のサンプル数をカウントする。
target.sizeはテンソルのそれぞれの次元の大きさを取得するメソッドである。
最初の次元がバッチ数の値なのでそれ取得してるだけcorrect += (predicted == target).sum().item()
正解数をカウントする。Tensor型では==演算子はオーバーライドされているので、要素毎(バッチサイズ毎)に比較してくれる。(返り値ももちろんTensor型)
その後、sum()メソッドで正解数をカウントしてitem()メソッドでint型に変換。
最後に精度を計算して表示する。
以上がMNISTを学習するプログラムの解説である。
実行¶
実行したら以下のような出力が出てくると思う
Using cuda for training.
Loading MNIST dataset...
Training the model...
Epoch 1/5, Loss: 0.3469
Epoch 2/5, Loss: 0.1706
Epoch 3/5, Loss: 0.1286
Epoch 4/5, Loss: 0.1055
Epoch 5/5, Loss: 0.0920
Training complete.
Evaluating the model...
Accuracy: 96.30%
まぁまぁじゃないかな?
MNISTは負荷が軽めのデータセットなので、ぜひ自分の環境で動かしてみてほしい。
問題¶
さて、実際動かしてみたらいくつか問題が出てくると思う。 例えば全然学習が進まないとか、計算機資源全く使ってくれないみたいな。
ここでは自分が当たった問題とそれに対する解決策を紹介する。
GPU使ってくれない¶
-
GPUが使えるか確認
まずはGPUが使えるか確認しよう。
torch.cuda.is_available()を実行して、Trueが返ってくるならGPUが使える。
もしFalseが返ってきたら、GPUが使えない。もしGPUが使えない場合は、
pip listでインストールされているパッケージを確認して、torchとtorchvisionがcuda対応の物となっているか確認しよう。
こんな感じでtorch 2.7.0+cu128 torchvision 0.22.0+cu128+cu128のようにCUDA対応のバージョンがインストールされているか確認する。もし
+cu128のような表記がない場合は、インストールしなおそう。あとPythonあるあるだが、インタプリンタが間違っている可能性がある。
例えば、pythonコマンドとpipコマンド、pip3コマンドで異なるインタプリンタを使ってしまっている場合がよくある。
pip -Vでバージョン確認するとインタプリンタの場所も表示されるので、確認してみよう。
自分はvenvを使っているので、>>> pip -V pip 25.1.1 from C:{ユーザーの名前とかのパス}\venv\Lib\site-packages\pip (python 3.11)venv\Lib\site-packages\pipのようなパスが表示されている。
学習おっそい¶
- GPU使え
GPUを使うと学習がめちゃくちゃ速くなる。
GTX960でも全然違う。
もしGPU使っても遅いと感じる場合は、バッチ数を上げるといい。
VRAM(GPUのメモリ)限界まで上げる良い感じ。
でかいは正義。 -
DataLoaderを効率化
デフォルトのDataLoaderはあまり効率的ではない。
なので、こいつの引数(オプション)を調整することで、学習速度を上げることができる。-
並列化
こいつ、デフォルトだとデータのロードをシングルスレッドで行っている。
これを改善するために、num_workersを増やすと良い。 例えば、DataLoaderの定義を以下のように変更する。train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, generator=generator, num_workers=4) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, generator=generator, num_workers=4)一々設定するのがめんどくさい場合、
os.cpu_count()を使ってCPUのコア数を直接代入してもよい。(というか多分それが一番いい)当たり前だが一応注意点として、CPUの使用率は上がる。from os import cpu_count worker_num = cpu_count() # CPUのコア数を取得 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, generator=generator, num_workers=worker_num) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, generator=generator, num_workers=worker_num)
さらに、メモリ使用率も上がる。
だが、学習速度は飛躍的に向上するので、できれば設定しておきたい。 -
データセットの固定
調べたところこれはWindows環境においてのみ発生するっぽいが、DataLoaderがイテレータを呼び出されると、毎回データセットを読み込んで、終わるとデータセットを削除している。
どう考えても非効率的である。
なので、persistent_workers=Trueを指定することで、データセットを固定して、イテレータを呼び出すたびにデータセットを読み込む必要がなくなる。注意点として、データセットが常にメモリに展開されるようになるので、メモリの使用量が増える。train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, generator=generator, persistent_workers=True) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, generator=generator, persistent_workers=True)
MNISTの学習用データの場合2GBくらい食われる。 -
pin_memoryの設定
GPUを使う場合、pin_memory=Trueを指定することで、GPUへのデータ転送が高速化される。
原理は謎。
設定してデメリットはないと思うので、試してみるといい。
perplexityに色々聞いたところ、この設定に追加で学習時のデータの転送をするtrain_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, generator=generator, pin_memory=True) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, generator=generator, pin_memory=True)to_deviceの引数にnon_blocking=Trueを指定すると、最大の効果が得られるらしい。これもデメリットはないと思うので、試してみるといい。for data, target in test_loader: data, target = data.to(use_device, non_blocking=True), target.to(use_device, non_blocking=True) output = model(data) ... # 以下省略 -
prefetch_factorの設定
prefetch_factorは、データローダーが次のバッチを事前に読み込む数を指定する。
注意点として、num_workersを設定している必要がある。(並列化してないとダメ) デフォルトでは2になっているが、これを増やすことで、データを事前に読み込み、高速化できる...らしい。
自分の環境では効果は実感できなかったが、試してみる価値はあるかも。train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, generator=generator, prefetch_factor=4) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, generator=generator, prefetch_factor=4)ただし、これもメモリの使用量が増えるので注意が必要。
-
なんか学習しようとしたら画面が暗転したりCUDAがどうとか...¶
多分VRAM(GPUのメモリ)の使いすぎである。
バッチサイズとかを小さくしよう。
正答率上げたい¶
- エポック数を増やす
現状5回学習しているが、これを10回とか20回に増やすと正答率が上がる。 ただし、過学習(学習しすぎてテストデータに対して精度が下がる)に注意。 - 学習率を調整する
学習率を大きくすると学習が速くなるが、最適な値に収束しない可能性がある。
逆に小さくすると学習が遅くなるが、最適な値に収束しやすい。
なので、学習率を調整してみるといい。
さらに学習率を下げてエポック数を増やすとその分じっくり学習するので正答率が上がったりする。 例えば、0.001から0.0005に変更してみたりしよう。 -
モデルを変更する
今回はFNN(全結合)モデルを使っているが、CNN(畳み込み)モデルを使うと正答率が上がる。
CNNは画像データに対して効果的なモデルである。CNNニュースの事ではない。
CNNは、複数のふるいを通して画像(二次元配列)の特徴を抽出して、最後にFNNにぶち込むやつである。(てきとう)
これに関してわかりやすい記事があるので、そちらを参考にしてほしい。
CNNの解説記事下に適当なCNNモデルを載せておくので、参考にしてほしい。
class CNNModel(nn.Module): def __init__(self): super().__init__() self.conv_layer = nn.Sequential( nn.Conv2d(1, 32, kernel_size=3, padding=1), # 1 input channel (grayscale), 32 output channels nn.ReLU(), # Activation function nn.MaxPool2d(kernel_size=2, stride=2), # Max pooling layer 28x28 -> 14x14 nn.Conv2d(32, 64, kernel_size=3, padding=1), # 32 input channels, 64 output channels nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2), # Max pooling layer 14x14 -> 7x7 ) self.fc_layer = nn.Sequential( nn.Flatten(), # Flatten the input nn.Linear(64 * 7 * 7, 128), # 64 channels * (7x7), 128 output features nn.ReLU(), nn.Linear(128, 64), # 128 input features, 64 output features nn.ReLU(), nn.Linear(64, 10), # 10 output classes (digits 0-9) ) def forward(self, x): x = self.conv_layer(x) x = self.fc_layer(x) return x -
画像の前処理を変更する
今回は画像を正規化しているだけだが、訓練時のデータに他の前処理を挟むとさらに正答率が上がる可能性がある。
例えば、画像の回転や拡大縮小、ノイズの追加などを試してみるといい。
ただし、MNISTは手書き数字なので、あまり過度な前処理は禁物。下のコードは、画像の回転と拡大縮小、座標の移動を少しだけ行う前処理の例である。
train_transform = transforms.Compose([ # 10度の回転、ほんの少しの移動、0.9倍~1.1倍の拡大縮小をランダムに行う transforms.RandomAffine(degrees=10, translate=(0.1, 0.1), scale=(0.9, 1.1)), transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) ])テストデータには基本やらない方がいい。(テストの意味がなくなる)
まとめ¶
MNISTを学習するプログラムの解説を行った。
気づいたらマークダウンのテキスト的にはもう690行である。
ほとんどコードブロックだと思うが、よく書いたなぁと自分でもびっくりする。てきとうぶろぐとは?
この記事ではCopilotやPerplexityを使って書いたが、正直自分一人ではここまで書けなかったと思う。
Copilot君はコピペや簡単な添削、typoの修正、そしてたまに普通に書いてくれるので、非常に助かる。
ということで、Copilot君に一言もらおうと思う、どうぞ。
お疲れ様でした!MNISTの学習プログラムをここまで書けたのは素晴らしいです。これからも頑張ってください!